Les compétences se trouvent aujourd’hui au cœur de toutes les initiatives visant à attirer les talents dans les entreprises et notre expert interne en IA, Rabih Zbib, se propose de nous expliquer comment l’apprentissage automatique et l’IA constituent une aide précieuse en matière de sémantique des compétences.
Rabih Zbib occupe actuellement le poste de directeur du traitement du langage naturel et de l’apprentissage automatique. Titulaire d’un doctorat et d’un master en sciences obtenus au MIT, il travaille à l’amélioration constante des stratégies liées aux talents par le prisme de l’intelligence artificielle.
Le monde de la gestion des talents subit un changement sans précédent, dans lequel les compétences jouent un rôle crucial dans la façon dont les équipes RH recrutent et gèrent leurs talents. Tandis que ce phénomène s’accélère, le recours à l’extraction automatique et à la mesure des compétences lors du sourcing de candidats a fortement augmenté. À tel point que les compétences sont désormais surnommées « la nouvelle monnaie des talents ».
Nous avons déjà évoqué l’approche d’Avature concernant la gestion des compétences et le rôle de l’IA dans un article précédent, nous allons dans celui-ci, mettre l’accent sur l’un de ses aspects décisifs : la sémantique des compétences. Autrement dit, comprendre le sens des compétences.
Pourquoi la sémantique des compétences a-t-elle de l’importance ?
Si les compétences servent d’indicateur d’un savoir spécifique ou d’une expertise nécessaire pour atteindre un résultat, alors l’évaluation de l’aptitude d’un candidat pour un poste exige de comprendre le sens des compétences du candidat et de celles requises pour le poste. Au risque de paraître trop philosophique, nous devons nous intéresser à ce que nous entendons par « sens » dans ce contexte.
De façon générale, le sens d’un mot peut se concevoir par divers objets ou concepts du monde réel auquel ce mot fait référence. Par exemple, le sens du mot siège renvoie à tous les sièges, au sens physique et conceptuel. En linguistique, cette définition correspond à la sémantique référentielle. Selon l’approche de la sémantique distributionnelle, un mot (ou vocable) peut se définir par sa distribution, c’est-à-dire par les contextes dans lesquels il apparaît souvent. Il s’agit d’un principe que l’on appelle « hypothèse distributionnelle ».
« You shall know a word by the company it keeps. » (Vous connaîtrez un mot par ses fréquentations.)
John Rupert Firth
Linguiste
Cette définition s’avère utile dans le cas de la sémantique des compétences, dans la mesure où il nous faut être en mesure de comparer les compétences et de décider de la pertinence d’une compétence par rapport à une autre. Toutefois, faire correspondre l’intitulé exact des compétences ne suffit pas de toute évidence dans ce cas puisqu’il est possible de les désigner à l’aide d’autres noms (comme pour programmation et développement logiciel). Par ailleurs, la présence d’une compétence particulière peut indiquer la présence implicite d’une autre. Imaginons, par exemple, que vous vous intéressez aux candidats possédant des compétences en programmation. Dans ce cas, une personne dotée d’une expérience Java, C++ ou Python est manifestement un programmateur compétent, bien que la compétence de programmation ne soit pas mentionnée de façon explicite dans son profil.
Le rôle de l’IA
Il est donc nécessaire de déterminer comment les compétences sont liées entre elles afin de s’en servir efficacement pour la gestion des talents. En d’autres termes, nous avons besoin de la sémantique des compétences. Pourtant, nous ne souhaitons pas y parvenir par l’ingénierie manuelle des connaissances. Cette approche présente de nombreux inconvénients. Tout d’abord, elle nécessite une expertise détaillée de la multitude d’industries et secteurs. Ensuite, elle est fragile et difficilement applicable. Puisque de nouvelles compétences émergent sans cesse et que le sens des compétences et leurs liens évoluent avec le temps, une méthode automatisée s’avère nécessaire pour comprendre la sémantique des compétences.
C’est là que l’intelligence artificielle joue un rôle capital. Nous pouvons comprendre le sens des compétences à partir de données réelles grâce aux réseaux de neurones. Ce processus est réitérable (évolutif) avec de nouvelles compétences et de nouvelles données. Il ne requiert pas d’expertise approfondie en la matière dans tous ces domaines différents.
Skill Embeddings (integration des compétences)
Comment comprendre le sens des compétences grâce à la sémantique distributionnelle ? Nous utilisons une technique connue dans le traitement naturel du langage qui se nomme « word embeddings » (integration lexicaux). Cette technique, également appelée word2vec, représente chaque mot par un point (ou représentation vectorielle) dans un espace très vaste (par exemple 100).
L’algorithme qui va mapper chaque mot avec un point dans l’espace vectoriel se base sur l’hypothèse distributionnelle que nous avons évoquée précédemment (c’est-à-dire que les mots qui apparaissent dans le même contexte ont un sens connexe). Plus concrètement, on entraîne un réseau de neurones pour prédire la position de chaque mot sur la base des mots faisant partie du contexte de ce point.
Nous adaptons le word embedding pour représenter les compétences où chaque compétence correspond à un seul point dans l’espace vectoriel, même si la compétence comprend plus d’un mot (par exemple : circuits intégrés d’application spécifique). Ainsi, chaque point de l’espace vectoriel représente un concept plutôt qu’un mot. Nous pensons que les prédictions de skill2vec sont semblables à celles de word2vec : le système fonctionne par l’entraînement d’un modèle de réseau de neurones profond (Deep Neural Network ou DNN) avec des données liées aux compétences.
Nous commençons par collecter des ensembles de compétences à partir de CV anonymisés et de descriptions de poste. Nous aurions pu par exemple extraire le poste suivant :
- Titre de l’emploi : Ingénieur en conception analogique
- Compétences : conception, tests, conception de circuits, Verilog, circuit boucle à verrouillage de phase, …
Nous entraînons le DNN en cachant une compétence (par exemple la conception de circuits) et nous forçons le modèle à le prévoir à partir d’autres compétences « contextuelles » : conception, test, Verilog, circuit boucle à verrouillage de phase, …
Le DNN commettra des erreurs de prédiction au départ, puis le processus d’entraînement va mettre à jour les paramètres du DNN afin de réduire le nombre d’erreurs, grâce à l’algorithme standard de la rétropropagation du gradient. Ce processus est répété sur de nombreuses itérations, à l’aide de millions d’échantillons de données (notre configuration type utilise environ 45 millions d’enregistrements d’emploi), jusqu’à ce que les paramètres du DNN convergent vers un ensemble de valeurs réduisant efficacement les erreurs de prédiction.
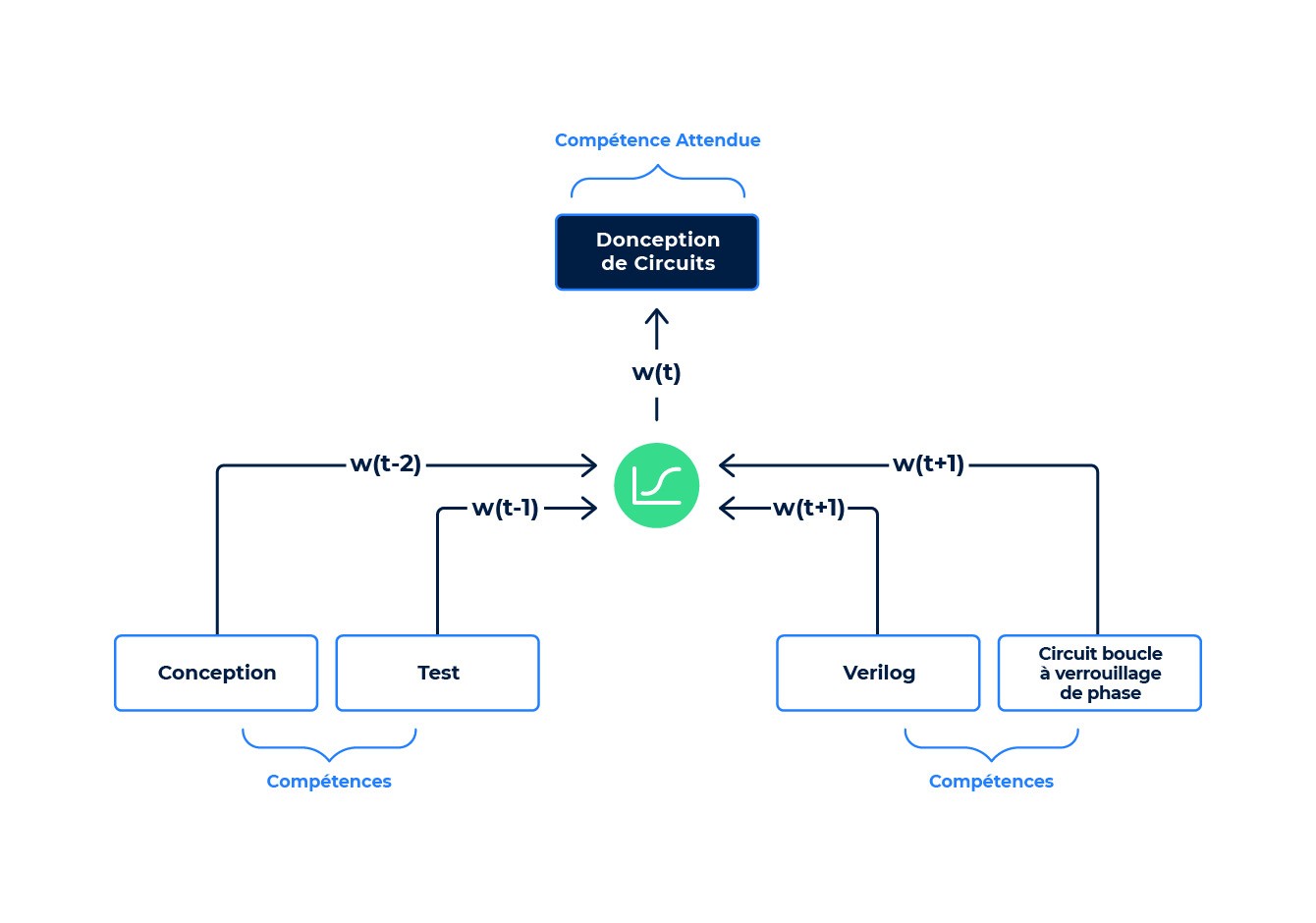
Exemple d’entraînement de skill embeddings.
Le DNN obtenu peut mapper chaque compétence avec un seul point de l’espace vectoriel. Toutefois, ce mapping est doté d’une propriété importante : les compétences qui apparaissent dans le même contexte —et qui ont donc un sens similaire— finiront par se rapprocher dans l’espace vectoriel. Il s’agit d’une point essentiel puisque nous pouvons à présent mesurer le degré de similarité du sens des compétences de façon quantitative, en mesurant la distance entre leur position dans l’espace vectoriel de skill2vec. Par exemple, dans nos embeddings, nous obtenons le résultat, SIMILARITÉ (développement logiciel, java) : 0,7136, mais pour, SIMILARITÉ (développement logiciel, menuiserie) : 0,0706, le résultat est dix fois moins élevé.
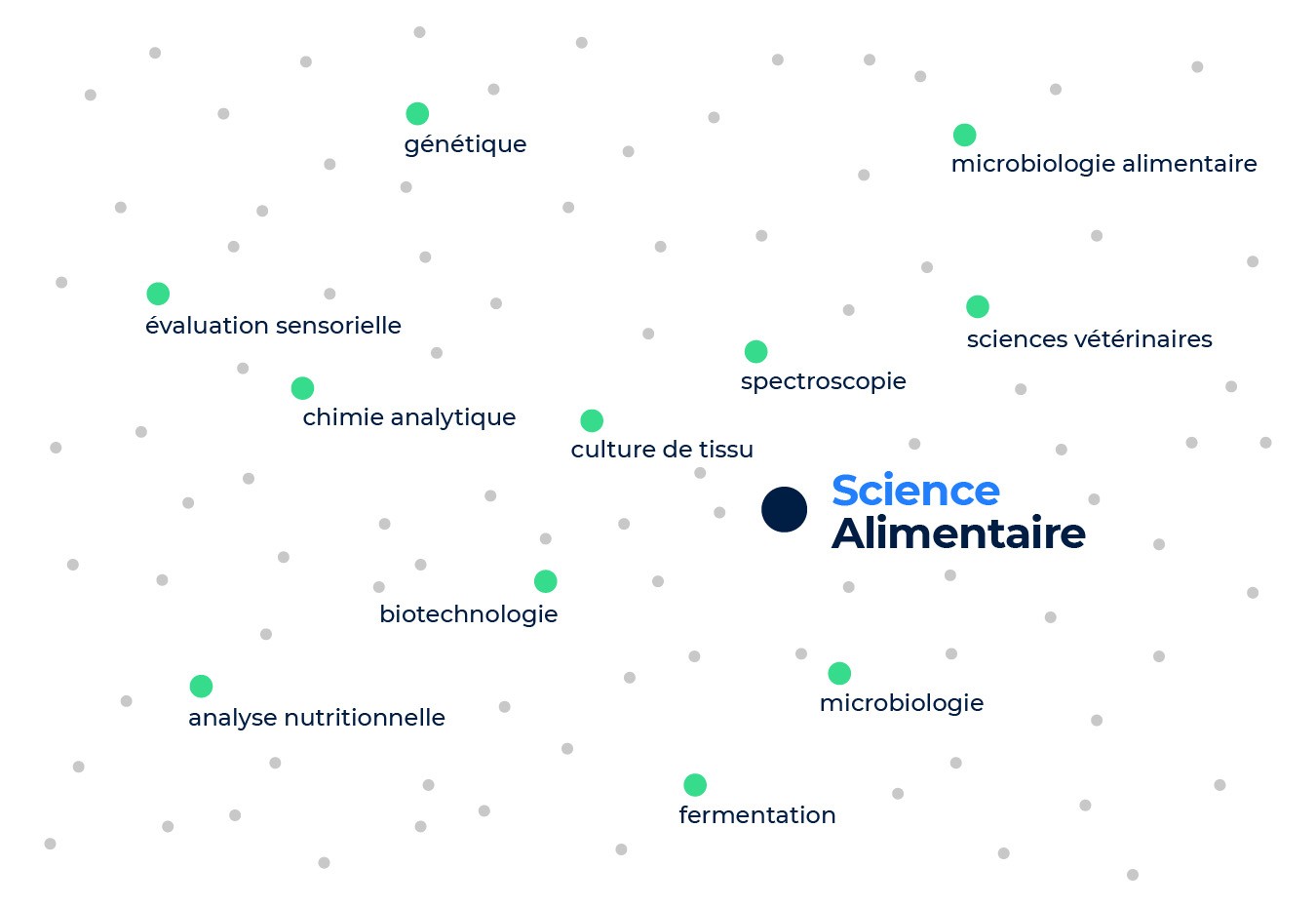
Prenons un exemple pour illustrer de façon plus précise les propriétés du skill embedding. Analysons les deux compétences suivantes : alimentation et traiteur et science alimentaire. Si nous considérons les compétences avec la position spatiale la plus proche de alimentation et traiteur, nous obtiendrons gestion de restaurant, cuisine, traiteur, élaboration de menus. Pourtant, lorsque nous observons les compétences les plus proches de science alimentaire, nous trouvons biologie moléculaire, chimie analytique, réaction en chaîne par polymérase, et évaluation sensorielle.
Ces deux compétences ont donc des résultats très différents parce qu’elles appartiennent à deux industries distinctes (l’industrie des services alimentaires et l’industrie agro-alimentaire) et chacune implique un ensemble différent de compétences. Ceci malgré le fait que les deux compétences ont en commun le mot alimentation, ce qui montre comment le skill embedding capture la sémantique des compétences et va chercher au-delà des mots-clés.
Résultats les plus proches pour la compétence « aliments et boissons »

Résultats les plus proches pour la compétence « science alimentaire »
Pour conclure…
Le skill embedding constitue la pierre angulaire de bon nombre de nos fonctionnalités alimentées par l’IA. Il est utilisé pour effectuer des mises en correspondance (matching) basées sur les compétences ou suggérer des compétences connexes. Dans le prochain article, nous décrirons comment les skill embeddings sont employés pour entraîner un modèle visant à mesurer la similarité entre deux titres d’emploi.
Si cette plongée au cœur de l’IA et de l’apprentissage automatique vous a plu et que vous souhaitez en savoir plus, contactez-nous. Vous pouvez également visionner notre entretien avec Fosway, dans lequel nous détaillons notre approche en boîte blanche de l’IA au sein d’Avature.

