Für Unternehmen, die ihren Kandidaten einen hohen Erlebniswert bieten wollen, sind intelligente Stellenempfehlungen zu einer Schlüsselfunktion von Karriereseiten geworden, um Besucher mit relevanten Angeboten zusammenzubringen. Die gleiche Technologie bietet auch Recruitern viele Vorteile, da sie den Prozess der Identifizierung qualifizierter Kandidaten beschleunigen kann.
Systeme mit Matching-Funktionen können mehrere Variablen berücksichtigen, von den Kompetenzen bis zum Bildungshintergrund, um die Kompatibilität zwischen Kandidaten und offenen Stellen zu ermitteln. Allerdings zählen die bisherige Berufserfahrung und insbesondere die Ähnlichkeit der Berufsbezeichnungen zu den wichtigsten Faktoren.
Aufbauend auf der Semantik der Kompetenzen hat unser Forschungsteam für maschinelles Lernen einen innovativen Ansatz für die semantische Ähnlichkeit von Berufsbezeichnungen entwickelt, der auf dem unüberwachten Repräsentationslernen basiert.
Wir haben uns mit unserem KI-Experten Rabih Zbib, Director of Natural Language Processing & Machine Learning, zusammengesetzt, um die wichtigsten Punkte dieser Arbeit zu besprechen, die in dem Forschungsbericht „Learning Job Titles Similarity from Noisy Skill Labels“ veröffentlicht wurde. Von der Art und Weise, wie das Modell trainiert wird und wie es funktioniert, bis hin zu den Vorteilen für Avature und unsere Kunden – lesen Sie weiter, um mehr über die robuste KI-Engine zu erfahren, die unsere Plattform antreibt.
Was ist an dieser Herangehensweise so interessant?
Wir wollten, dass unser Modell zwei Berufsbezeichnungen vergleicht und daraus ableitet, wie ähnlich sich diese sind. Die herkömmliche Lösung für dieses Ziel besteht darin, ein überwachtes Modell zu entwickeln, das auf einem sehr großen Datensatz von Paaren von Berufsbezeichnungen trainiert wird, die von Menschen manuell annotiert werden, um zu entscheiden, ob sie einander ähnlich sind oder nicht. Da die Annotation eines ausreichend großen Datensatzes jedoch ein langsamer und unflexibler Prozess ist, haben unsere ML-Forscher einen anderen Ansatz gewählt und das Modell mit semantischen Repräsentationen der Berufsbezeichnung trainiert.
Wir werden später auf die technischen Details des Modells eingehen, doch zunächst einmal hat das resultierende Modell zwei wichtige Eigenschaften, die es von anderen Ansätzen auf dem Markt unterscheiden:
- Es basiert auf unüberwachtem Lernen – einer wahrhaft revolutionären Methode in der KI – und ist daher verallgemeinerbar, kosteneffizienter und leichter mit mehr Daten zu erweitern, da es keine menschlichen Annotationen benötigt.
- Dies ermöglicht eine schnellere Entwicklung und Bereitstellung, was unseren Kunden kurz- und langfristig erhebliche Vorteile bringt.
Warum diese Richtung einschlagen?
Die treibende Kraft hinter der Innovation bei Avature ist die Schaffung von Mehrwert für unsere Kunden durch die Bereitstellung leistungsstarker Tools zur Verbesserung ihrer Talentprozesse. Und in diesem Fall ist es nicht anders. Wir haben uns für diesen Ansatz entschieden, weil er zahlreiche Vorteile für unsere Kunden bringt:
- Die Anwendungsfälle, die wir durch KI ermöglichen, sparen den Recruitern unserer Kunden viel Zeit und ermöglichen es ihnen, die Erfahrungen aller Beteiligten in talentbezogenen Prozessen zu verbessern. Indem wir neue Modelle einführen, um unsere plattformübergreifenden KI-Funktionen zu stärken und sie schnell zu implementieren, stellen wir auch sicher, dass unsere Kunden weiterhin von diesen Vorteilen profitieren.
- Da das Modell auf semantischer Ebene arbeitet, ermöglicht es einen intelligenten Vergleich von Berufsbezeichnungen und nicht nur einen oberflächlichen Vergleich von Schlüsselwörtern. Darüber hinaus lässt sich das Modell verallgemeinern, d. h. es kann die Ähnlichkeit auch für Berufsbezeichnungen vorhersagen, die nicht in den Daten enthalten waren, mit denen das Modell trainiert wurde. Das ist ein großer Vorteil, denn in der Arbeitswelt gibt es immer wieder neue Berufsbezeichnungen.
- Da wir unser ML-Modell ohne menschliche Annotationen erstellen können, können wir es schneller aktualisieren und so verhindern, dass das Modell veraltet. Während sich der Arbeitsmarkt verändert, können wir unsere KI-Kerntechnologie regelmäßig aktualisieren, um dafür zu sorgen, dass unsere Kunden stets genaue Ergebnisse erhalten und die negativen Auswirkungen der Modelldrift vermieden werden.
- Die semantischen Repräsentationen, die für das Training des Berufsbezeichnungsmodells verwendet werden, sind sprachunabhängig. Mit diesem Ansatz haben wir unsere Funktionen neben Englisch auch in Französisch, Deutsch, Spanisch und Italienisch entwickelt, und viele weitere Sprachen stehen auf unserer Roadmap. Für unsere globalen Kunden, die in vielen verschiedenen Ländern tätig sind, ist die Möglichkeit, unsere KI-Funktionen konsistent in mehreren Sprachen zu nutzen, unglaublich wertvoll.
Wie das Modell funktioniert
In unserem letzten Blogbeitrag über die Semantik von Kompetenzen haben wir beschrieben, wie Kompetenzen als Vektoren oder Punkte in einem hochdimensionalen semantischen Raum modelliert werden. Wir haben erklärt, wie dieser Raum, der mit einem Modell eines neuronalen Netzes konstruiert wurde, das auf realen Daten trainiert wurde, es uns ermöglicht, den Grad der Ähnlichkeit zwischen den Kompetenzen anhand des Abstands zwischen ihren entsprechenden Punkten in diesem Raum zu messen. Die Semantik der Kompetenzen wird durch diese Vektoren (sogenannte Einbettungen) repräsentiert, was als Repräsentationslernen bezeichnet wird.
Nun zurück zu den Berufsbezeichnungen. Das Team von Avature ML kam zu dem Schluss, dass eine Repräsentation der Berufsbezeichnung aus der Repräsentation der damit verbundenen Kompetenzen abgeleitet werden kann. Zu diesem Zweck extrahierten sie Kompetenzen aus Millionen von Stellenausschreibungen und aus den Abschnitten über die Berufserfahrung in anonymisierten Lebensläufen und ordneten sie den entsprechenden Berufsbezeichnungen zu.
Dies wurde mit einem sehr großen Datensatz durchgeführt. Kompetenzen, die aus verschiedenen Datensätzen extrahiert wurden, aber derselben Berufsbezeichnung entsprechen, wurden kombiniert, um zu verfolgen, wie oft eine Kompetenz mit derselben Berufsbezeichnung gefunden wurde. Das Ergebnis sah in etwa so aus:
Director of Communications: { „Public Relations“:135, „Social Media“: 128, „Kampagnen“: 93, „Schreiben“: 55, „Strategie“: 18, … }
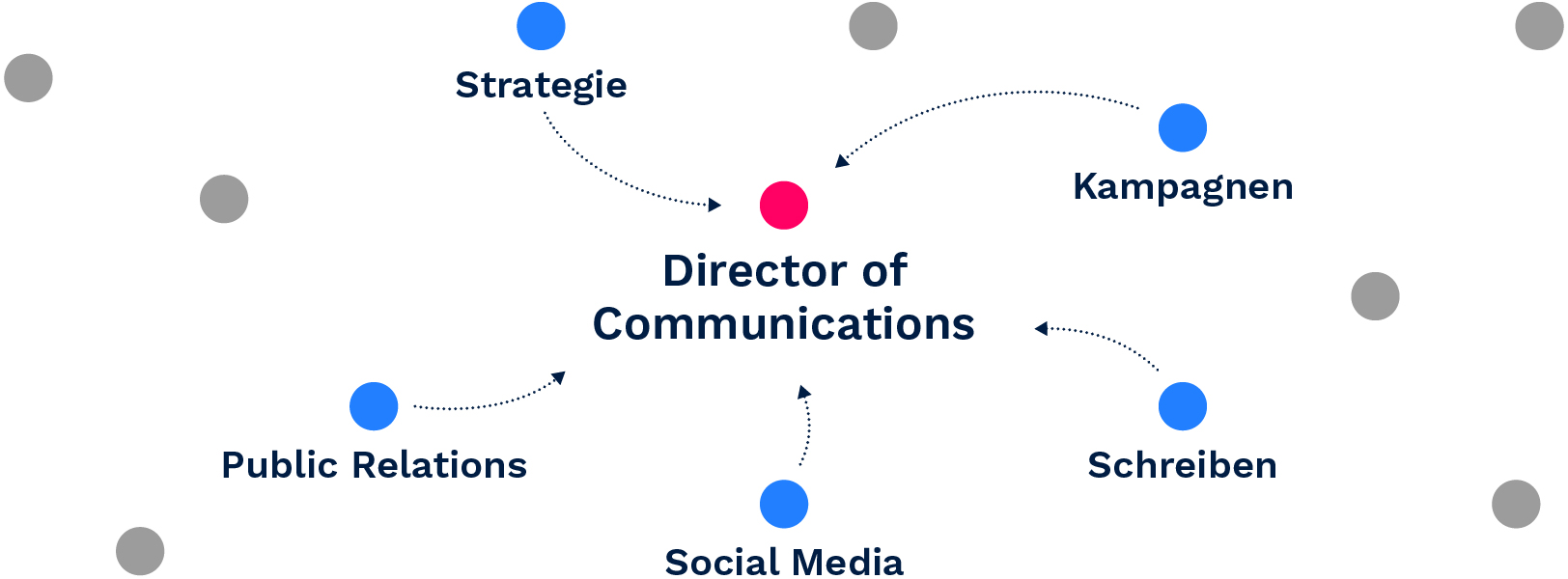
Abbildung 1. Die Repräsentation einer Berufsbezeichnung aus den zugehörigen Kompetenzen ableiten.
Eine semantische Repräsentation der Berufsbezeichnung kann dann durch die Mittelung der Einbettungsvektoren aller verwandten Kompetenzen und die Verwendung der Punktzahlen als Gewichte, die die Bedeutung der einzelnen Kompetenzen widerspiegeln, gewonnen werden. Diese Repräsentation kann direkt zum Vergleich von Berufsbezeichnungen verwendet werden.
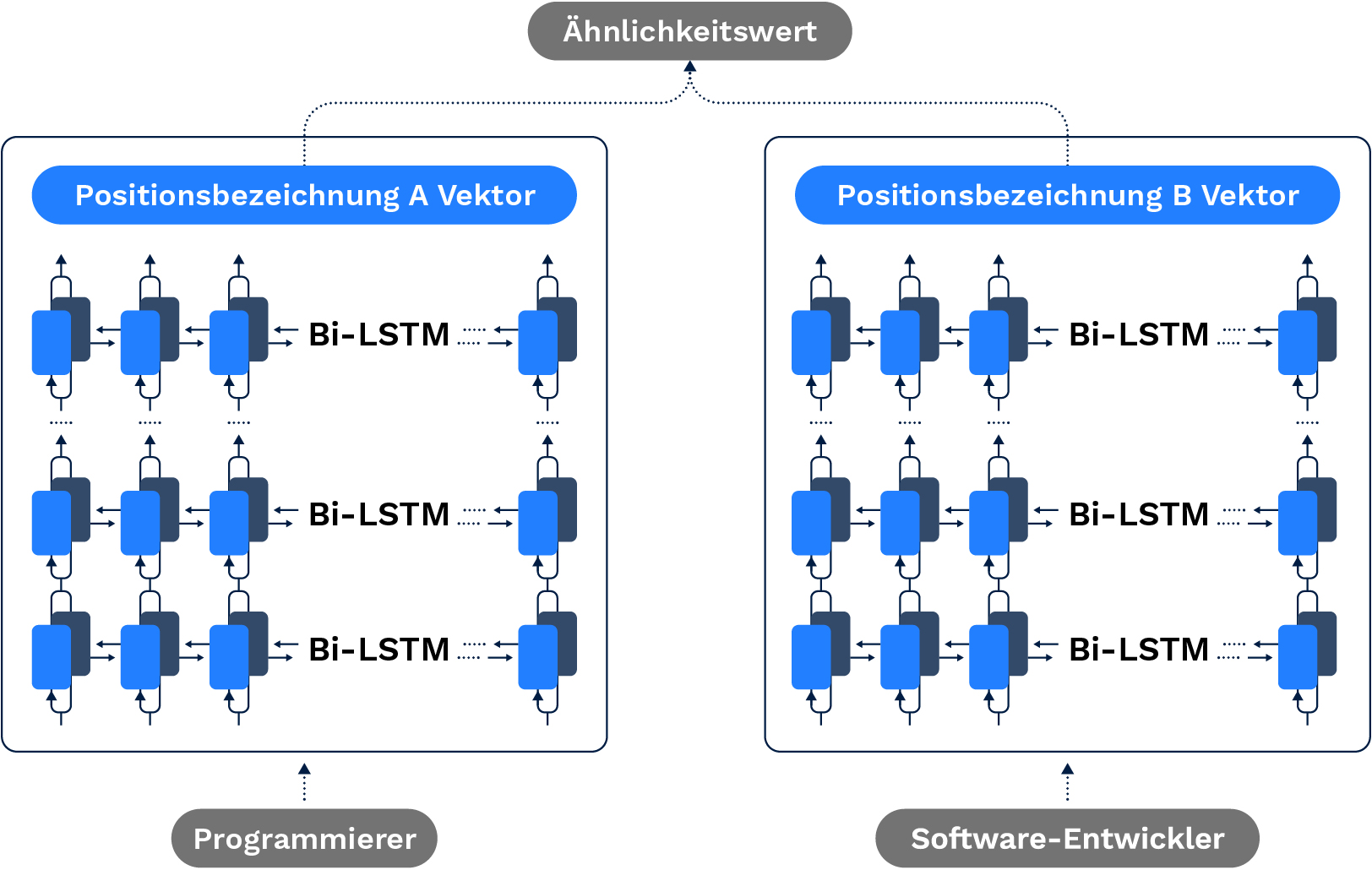
Abbildung 2. Beispiel für die Anwendung des Berufsbezeichnungsmodells. Die rekurrenten neuronalen Netze erzeugen für jede Bezeichnung einen Einbettungsvektor, der die Semantik der Berufsbezeichnung erfasst. Zwei Vektoren werden dann verglichen, um die Ähnlichkeit zwischen ihren entsprechenden Einbettungen zu bestimmen.
Dies wäre jedoch auf Berufsbezeichnungen beschränkt, die in den Trainingsdaten häufig genug vorkommen. Um sicherzustellen, dass das Modell verallgemeinert werden kann, wollten wir noch weiter gehen. Unsere Forscher verwendeten diese Daten stattdessen als ideale Repräsentationen der Berufsbezeichnungen (oder „Ziele“ in der KI-Terminologie) und trainierten ein rekurrentes neuronales Netzwerk (RNN) darauf, diese ideale Repräsentation nachzubilden.
Einmal trainiert, kann das RNN dann eine solche Repräsentation aus der Berufsbezeichnung erzeugen. Dies schließt auch neue Berufsbezeichnungen ein, die in den Trainingsdaten noch nicht vorkamen.
Ein weiteres wichtiges Merkmal dieses Modells ist, dass es keine verwandten Kompetenzen benötigt, um die Einbettung einer Berufsbezeichnung zu erzeugen. Die entsprechenden Kompetenzen werden nur zum Trainieren des Modells verwendet. Und so hat das Team das Ziel erreicht, das wir uns selbst gesetzt hatten: Ein Modell, das in der Lage ist, zwei Berufsbezeichnungen auf der Grundlage ihrer Semantik zu vergleichen, und das bemerkenswerterweise mit unüberwachten Repräsentationen anstelle der langsamen und kostspieligen manuellen Annotation trainiert wurde.
Die Verwendung der Semantik von Kompetenzen als Repräsentation von Berufsbezeichnungen ermöglicht es uns auch, den größten Engpass in der KI-Entwicklung zu überwinden: die Daten. Auch wenn Kompetenzen in einer bestimmten Sprache, z. B. Englisch, ausgedrückt werden, sind sie als Konzepte sprachunabhängig. „Public Relations“ hat immer noch etwas mit „Social Media“ zu tun, egal, ob diese Kompetenzen auf Englisch oder Deutsch ausgedrückt werden. Das bedeutet, dass wir, um Trainingsdaten in einer neuen Sprache zu erhalten, nur die Berufsbezeichnungen dieser Daten übersetzen und die semantische Repräsentation unverändert wiederverwenden können. Dank dieser Eigenschaft können wir die KI-Modelle in neuen Sprachen trainieren und unsere KI-Fähigkeiten in diesen Sprachen in Rekordzeit anbieten.
Entwicklung für Transparenz und Flexibilität
Tools wie ChatGPT haben KI in einer Weise in den Mainstream katapultiert, wie wir es noch nie zuvor erlebt haben. Aber die Diskussionen und Bedenken über diese Technologie im Recruiting sind nicht neu. Diese Bedenken sind auch der Grund für die zunehmende Regulierung in diesem Bereich. So hat beispielsweise die Stadt New York ein Gesetz verabschiedet, das Arbeitgeber verpflichtet, Voreingenommenheitskontrollen durchzuführen bei automatisierten Personalentscheidungen, einschließlich solcher, bei denen KI zum Einsatz kommt.
Da wir wissen, wie wichtig es für unsere Kunden ist, unvoreingenommene und faire Talentprozesse zu gewährleisten, trainieren wir unsere nativen KI-Modelle nicht mit persönlichen Daten wie Ethnie, Alter, Geburtsort und Geschlecht. Wir vermeiden auch implizite Voreingenommenheit, indem wir keine historischen Daten menschlicher Entscheidungen verwenden, um unsere KI-Modelle zu trainieren. Stattdessen ist unser Ansatz repräsentationsbasiert, d. h. wir modellieren die Semantik der Attribute des Kandidatenprofils, wie z. B. die Kompetenzen oder die Berufsbezeichnung. Unsere Trainingsmethode für das Berufsbezeichnungsmodell passt zu dieser Philosophie.
Aber die Prämisse der Transparenz geht über das Modelltraining hinaus. Die Verwendung eines repräsentationsbasierten Modells für jede Art von Attribut ermöglicht unseren White-Box-Ansatz für KI, der den Avature-Benutzern vollständige Einsicht und Kontrolle über die internen Abläufe des Systems gibt, sodass ihre Entscheidungsfindung verbessert, aber nicht ersetzt wird.
Zunächst mit der Semantik von Kompetenzen und nun mit der Ähnlichkeit von Berufsbezeichnungen streben wir die Entwicklung von ML-Modellen an, die effektive Lösungen zur Optimierung der Recruiting- und Talentmanagementprogramme unserer Kunden ermöglichen. Unser wichtigstes Ziel ist es, flexible Technologien zu entwickeln, die den Herausforderungen der Zukunft gewachsen sind.
Vor einigen Jahren haben wir uns entschieden, unsere KI-Algorithmen selbst zu entwickeln. So können wir eng mit unseren Kunden zusammenarbeiten und Innovationen entwickeln, die ihren Visionen und Bedürfnissen entsprechen. Für sie bedeutet dies, dass sie vollen Zugang zu den Experten hinter den Modellen haben, was bei Anbietern, die ihre KI-Entwicklung auslagern, mitunter nicht der Fall ist. Wenn auch Sie mit unseren Experten sprechen möchten, um mehr über unsere ML-Modelle und unsere KI-Fähigkeiten im Allgemeinen zu erfahren, kontaktieren Sie uns.
Das vollständige Dokument ist unter folgendem Link abrufbar:
Rabih Zbib, Lucas Lacasa Alvarez, Federico Retyk, Rus Poves, Juan Aizpuru, Hermenegildo Fabregat, Vaidotas Simkus and Emilia Garcıa-Casademont, 2022, Learning Job Titles Similarity from Noisy Skill Labels, arXiv: 2207.00494 [cs.IR]


